The Phone Maker That Just Changed AI Inference
On a Monday morning that surprised the technology industry, Xiaomi did something that few observers expected. The company best known for affordable smartphones, electric scooters, and home air purifiers announced that it had broken a major barrier in artificial intelligence speed. Its new MiMo-V2.5-Pro-UltraSpeed serving mode generates more than 1,000 tokens per second on a one trillion parameter model, peaking near 1,200 tokens in live demonstrations. This is not a stripped down version of the model. It is the full MiMo-V2.5-Pro flagship, a frontier level AI system that rivals Claude Opus on coding benchmarks.
- The Phone Maker That Just Changed AI Inference
- What 1,000 Tokens Per Second Actually Means
- How Xiaomi Outpaced Custom Chip Giants
- Inside the Three Techniques Driving UltraSpeed
- Why Speed Unlocks Entirely New Applications
- Access, Pricing, and Open Source Release
- Xiaomi’s Quiet Rise as an AI Powerhouse
- At a Glance
What makes the announcement startling is not just the speed. It is the hardware that delivers it. Xiaomi achieved these numbers using a single standard node with eight commodity GPUs, the kind of equipment available from any major cloud provider. No custom silicon. No specialized chips the size of dinner plates. Just software innovations running on hardware that developers can rent tonight.
Parameters are the internal numerical weights that define how an AI model processes information. A trillion parameters means the model can recognize extraordinarily complex patterns across text and code. Tokens are the chunks of text the model reads and writes, roughly three quarters of a word each. Generating over 1,000 of them each second means this massive brain is operating at a pace that was previously considered impossible without dedicated hardware.
For years, the race for faster AI inference has been dominated by well funded chip startups with custom silicon designs. Xiaomi just proved that clever engineering on standard equipment can leapfrog them all. The achievement raises a pointed question about whether expensive specialized hardware is necessary when intelligent software optimization can deliver superior results on accessible infrastructure.
What 1,000 Tokens Per Second Actually Means
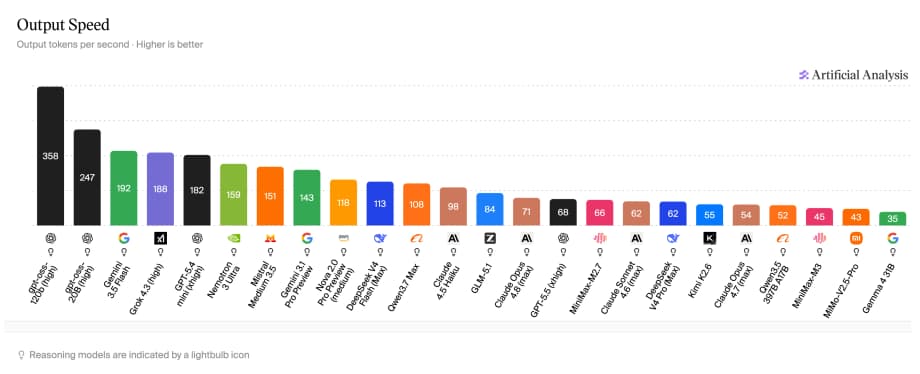
To understand why this number matters, look at what everyday users experience today. According to benchmark data from Artificial Analysis, GPT-5.5, the model powering most ChatGPT conversations, generates approximately 68 tokens per second. Claude Opus 4.6 operates at around 71 tokens per second, while Anthropic’s lighter Haiku model reaches 98. Google’s Gemini Flash moves faster at 192 tokens per second. MiMo-V2.5-Pro-UltraSpeed hits 1,000 tokens per second on a model with one trillion parameters, nearly fifteen times faster than the chatbots millions of people use daily.
The gap between 68 and 1,000 is not merely incremental. It represents an entirely different category of performance. At current consumer speeds, users wait several seconds for a paragraph of text to appear. At Xiaomi’s new speed, a full page of analysis can materialize almost instantly. For developers running coding agents, the difference transforms the experience from a delayed back and forth into something resembling real time collaboration.
Tokens serve as the basic currency of large language models. When you type a prompt, the model breaks your text into tokens for processing. When it replies, it generates tokens one by one, predicting each based on everything that came before. The faster a model can generate tokens, the more responsive it feels and the more tasks it can complete within strict time limits. Speed also determines how many requests a server can handle simultaneously, directly affecting cost and scalability for businesses.
MiMo-V2.5-Pro’s earlier Flash model already generated responses at 150 tokens per second, roughly 110 words per second, faster than the fastest human can read or speak. UltraSpeed pushes that ceiling dramatically higher, creating a generation rate that outpaces human cognition and enables machine driven workflows that were never before possible.
How Xiaomi Outpaced Custom Chip Giants
The AI inference speed bottleneck has attracted hundreds of millions of dollars in investment from companies building specialized hardware. Cerebras designed a wafer scale chip roughly the size of a dinner plate, packing 44GB of on chip memory to eliminate bandwidth constraints. That design hit 969 tokens per second, an impressive feat, but on Meta’s Llama 3.1 405B, a model with 405 billion parameters. That is less than half the size of MiMo-V2.5-Pro. Groq built a custom Language Processing Unit architecture capable of 300 to 750 tokens per second depending on the model. Neither system runs on standard cloud hardware that developers can rent from providers like AWS.
Xiaomi’s approach inverts that model entirely. Working with inference partner TileRT, the company achieved its record through what it calls extreme model system codesign, a coordinated optimization of both the AI model and the software engine serving it. The result is a trillion parameter model running faster than specialized silicon on commodity GPUs. If independent testing confirms these benchmarks, the achievement suggests that software innovation can overcome hardware limitations that many assumed required custom chips.
This development carries real economic weight. Custom silicon requires enormous capital expenditure, lengthy design cycles, and specialized manufacturing. Commodity GPUs benefit from economies of scale, widespread availability, and constant iterative improvements from NVIDIA and other manufacturers. By solving the inference problem through software, Xiaomi has potentially democratized access to speeds that were previously reserved for well funded labs with proprietary hardware.
The release of the FP4-DFlash checkpoint on Hugging Face adds another dimension to this democratization. Researchers and developers worldwide can now inspect, test, and adapt the underlying model without purchasing proprietary hardware or securing enterprise licenses. Community validation will determine whether these techniques transfer broadly across different models and use cases.
Inside the Three Techniques Driving UltraSpeed
The breakthrough relies on three coordinated techniques that work together. None achieves the speed record alone, but combined they push performance past the 1,000 token threshold.
The first technique is FP4 quantization. Most large models run at 16 bit or 8 bit numerical precision, meaning each parameter requires two bytes or one byte of memory. Xiaomi compresses the expert layers, which constitute the majority of the one trillion parameters, down to 4 bit precision. This cuts the memory footprint and reduces bandwidth pressure, allowing data to move faster through the system. The risk with quantization is quality loss, as lower precision can degrade a model’s reasoning ability. Xiaomi’s workaround is surgical; only the expert layers receive compression while the rest of the model stays at full precision. The company describes the resulting quality loss as near zero.
The second technique is DFlash speculative decoding. Traditional speculative decoding uses a smaller draft model to guess the next few tokens quickly, then has the large model verify those guesses in parallel. DFlash eliminates the sequential drafting step entirely. Instead, it fills an entire block of masked positions in a single forward pass. During coding tasks, the large model accepts an average of 6.3 out of 8 proposed tokens per verification round. That means six tokens advance in one step instead of one, a massive acceleration in generation speed.
The third component is TileRT itself, the inference engine that keeps the entire compute pipeline continuously resident inside the GPU. Standard serving systems often launch individual operators one by one, creating small gaps in execution. TileRT removes that per operator launch overhead and keeps the data flowing without interruption. When combined with the compressed model weights and the advanced decoding strategy, the engine sustains throughput levels that were previously unreachable on standard hardware.
Xiaomi calls this combination extreme model system codesign, and the description fits. Each layer of optimization reinforces the others, creating a whole that exceeds what any single technique could deliver independently.
Why Speed Unlocks Entirely New Applications
Raw benchmarks are meaningless unless they enable something new. At 1,000 tokens per second, MiMo-V2.5-Pro-UltraSpeed opens doors that remain firmly shut to slower systems.
Consider how developers currently use large language models for complex tasks. When facing a difficult coding problem, a user typically waits for one answer and hopes it is correct. With UltraSpeed, the same user can run dozens of reasoning paths in parallel within the same real time window, automatically verifying and self correcting in the background. The model can explore multiple solutions simultaneously rather than committing to a single chain of thought. This capability fundamentally transforms AI from a sequential assistant into a parallel problem solver.
Industries with hard latency constraints stand to benefit immediately. Fraud detection systems must evaluate transactions in milliseconds. Real time trading signal generation cannot afford multi second delays. Autonomous agent loops, where AI systems observe, decide, and act in rapid cycles, require speeds that consumer chatbots cannot deliver. At 68 tokens per second, these applications face frustrating bottlenecks. At 1,000 tokens per second, they become viable on standard cloud infrastructure.
Even in everyday coding workflows, the speed changes psychology. Developers previously stared at screens waiting for inference to complete. With output approaching and exceeding 1,000 tokens per second, the delay effectively vanishes. The interaction shifts from requesting and waiting to genuine real time collaboration with an AI partner. Healthcare applications requiring rapid analysis of patient data and investment platforms processing live market feeds both gain immediate practical value from this level of responsiveness.
Access, Pricing, and Open Source Release
Xiaomi is not keeping this technology behind a locked door. The company has launched a limited API trial running from June 9 through June 23, 2026. Access is application based, and approval is not guaranteed. Priority goes to enterprise users and professional developers with concrete business needs. Due to limited high speed inference resources, each account can join the queue up to ten times per day, with each session capped at thirty minutes. Sessions idle for more than five minutes will be automatically released.
The pricing structure reflects the premium nature of the speed. UltraSpeed costs three times the standard MiMo-V2.5-Pro rate, but delivers approximately ten times the generation speed. For context, the standard MiMo-V2.5-Pro already undercuts Claude Opus dramatically, charging roughly $0.43 per million input tokens and $0.87 per million output tokens compared to Opus at $5 input and $25 output per million tokens. Even at triple the rate, Xiaomi’s accelerated offering remains far less expensive than many competing frontier models.
For developers who prefer to test the technology directly, Xiaomi has released the underlying MiMo-V2.5-Pro-FP4-DFlash checkpoint as open source on Hugging Face. TileRT has also released select modules on GitHub. This move invites the global research community to verify the benchmarks, experiment with the architecture, and potentially adapt the techniques for other models. Independent third party verification is not yet widely published, so community testing through these open releases will serve as the real proof over the coming weeks.
Xiaomi’s Quiet Rise as an AI Powerhouse
For most consumers, Xiaomi remains the brand that sells affordable electronics. The company has sold millions of smartphones, electric scooters, and air purifiers across global markets. That consumer image has masked a steadily growing artificial intelligence division that most of the industry ignored until now.
MiMo-V2.5-Pro already matched Claude Opus on most coding benchmarks when it launched in April. UltraSpeed does not introduce a new or dumbed down model. It accelerates the exact same frontier level intelligence that was already competing at the top tier. The phone brand has effectively built an AI capability that rivals dedicated labs while maintaining pricing that undercuts them by an order of magnitude.
If the speed claims hold up under independent scrutiny, Xiaomi will have achieved something extraordinary without the hundreds of millions of dollars in custom silicon investment that companies like Cerebras and Groq required. It will have demonstrated that software optimization on commodity hardware can deliver category leading performance. That result would reshape assumptions about where AI capability comes from and which players can compete at the frontier. A consumer electronics giant from Beijing just joined the top tier of AI infrastructure innovators, and it arrived carrying standard GPUs rather than custom silicon.
At a Glance
- Xiaomi’s MiMo-V2.5-Pro-UltraSpeed generates over 1,000 tokens per second on a one trillion parameter model using only eight standard commodity GPUs, with no custom silicon required.
- The speed is roughly fifteen times faster than GPT-5.5 and Claude Opus, and was achieved through FP4 quantization, DFlash speculative decoding, and the TileRT inference engine.
- A limited API trial runs from June 9 to June 23, 2026, priced at three times the standard MiMo rate for approximately ten times the generation speed, with priority given to enterprise and professional developers.
- Xiaomi has released the FP4-DFlash checkpoint as open source on Hugging Face, allowing community verification and adaptation of the techniques.
- If independently verified, the breakthrough suggests that software optimization on standard cloud hardware can outperform expensive custom chip solutions from specialized AI hardware companies.









